DeepSeek Presented Simple
A mid in-depth technical review on how DeepSeek was developed

Introduction
In January 2025, DeepSeek (deepseek.com), a Chinese startup, unveiled its revolutionary AI model, transforming the artificial intelligence landscape with its exceptional performance-to-cost ratio compared to US and other West AI models. Alongside their model release, they launched a mobile app enabling real-time AI interactions similar to ChatGPT and Claude. The app cultivated over 10 million downloads on the Google Play Store within its first few weeks of release. Its rocketing growth reminds of the first days of ChatGPT release.
What drove DeepSeek’s R1 to such popularity? Well, their open-source (Well, not technically fully open-source) model delivers impressive performance comparable to leading Western open-source AI counterparts like Llama and Mixtral. They also offers a web and API interface access with huge cost cutoffs compared to the closed-source market. Furthermore, their performance rivals the cutting-edge models: OpenAI’s ChatGPT o1 (released very recently) and Anthropic’s Claude 3.5 Sonnet, even surpassing them on some benchmarks. They achieved this performance while reducing costs by more than 95% (1M output token: 60$ OpenAI o1 - 2.19$ DeepSeek). This causes significant market disruption leading to an approximate collapse of $1 trillion in market value. Nvidia, the GPU industry leader, experienced an unprecedented $600 billion loss in market capital, marking the largest single-company loss in U.S. stock market history!
Perhaps most significantly, DeepSeek published their work as open-source under an MIT license (R1 is fully MIT at least, till now). This makes their models commercially permissible given the compute. Additionally, their experimental work is thoroughly well-documented in published technical reports covering both DeepSeek R1 and DeepSeek V3. They also have published works for the elder DeepSeek V3 models, V2, and V1. Such initiative represents a major leap for open-source progress in the AI race against closed-source companies.
But Wait! There is an Ahaa moment that I can flag here! How did DeepSeek achieve such impressive performance given China’s export controls? Note that the company reported training this model on a cluster of 2,048 Nvidia H800 GPUs. These GPUs are less efficient than their powerful sibling: the Nvidia H100. While they both have the same FLOP/s ratio, H800 are slower in their communication (see this clip from Lex Fridman podcast), although this is still a skeptical side of the story for many, especially conspiracy theorists given the current US-China rivalry. One aspect of this notable performance boost is their thorough and numerous experimentations,dedication, innovation, and brilliant engineering efforts with various and ablation studies. As a result of this hard work, they introduced wild conclusions that shocks the AI community. For instance, Reinforcement Learning (RL) can fully replace the supervised fine-tuning phase of LLMs development pipeline. Aside from this amuzing conclusion, this step is usually a tedious task as it involves the collection of high quality data with cumbersome human annotations.
In this article, I will explain and overview how this model was trained with some technical depth. I will also try to shade lights on what makes it unique among its counterparts underscoring the innovations they made. This will also cover the development of its predecessor, DeepSeek V3, as understanding both is instrumental for grasping the complete picture. It is always, however, better to take a look and dive into their technical reports for deeper insights.
This article begins with a preamble introducing key terminology to establish common ground. It then discusses DeepSeek-R1, followed by DeepSeek-V3.
Preamble and Terminologies
Before diving deeper, it’s useful to establish a common ground so that both of us (me and you) can follow the technical discussion with a clear alignment to the context. This preamble will introduce two main topics that are relative to our discussion: The typical LLM development pipeline, and MoE architecture.
An LLM Development Pipeline
The development of a production-grade LLM typically involves the following steps:
Dataset Creation: Building a massive text dataset (usually containing trillions of tokens) comprising books, articles, high-quality web content, wiki pages, and other text sources. Nothing fancy here. The main focus in this stage is on collecting high-quality data with meticulous preprocessing to ensure the quality constrains.
Base Model Training: Developing and training a transformer-based model for the next-token prediction objective on the collected dataset. The resulting trained model (usually called a base model) should be smart enough to predict the most probable next token given a sequence of previous tokens.
Supervised Fine-tuning (SFT): The base model undergoes additional fine-tuning on datasets from downstream NLP tasks such as text classification, question answering, sentiment analysis, machine translation, language understanding and comprehension, etc. These datasets follow a specific format with input-output pairs, and the model is fine-tuned to generate appropriate outputs for given inputs. In this stage, the model is trained with a variety of prompts to help generalizing to a wide range of inputs variations. The model after this step is usally called an instruct model.
Alignment: While the model seems to be ready for the public use from the previous step, this final step further ensures that the model aligns its output with human preferences by avoiding harmful, offensive, or disrespectful content. This typically involves a process of tuning called Reinforcement Learning from Human Feedback (RLHF). The model, in this step, is tuned to follow human preferences. The resulting model after this step is a production-ready LLM, often called a Chat model (like ChatGPT). In some cases, this step is combined with the previous fine-tuning step in the technical reports.

Figure 1: LLM Development Pipeline
MoE architecture
DeepSeek V3 employs a Mixture of Experts (MoE) architecture. This design incorporates multiple specialized subnetworks (experts) trained together during training, with only few of them are activated during inference. Each expert develops proficiency in processing different types of inputs or tasks. During user interaction, the architecture’s gating mechanism routes to the most appropriate expert(s) based on the input.
A common misconception about MoE is that experts specialize in specific domains (like mathematics or creative writing). While theoretically possible (and already tried, see: Branch-Train-MiX: Mixing Expert LLMs into a Mixture-of-Experts LLM), practical implementations typically have experts learnt to process different data patterns rather than explicit domain specialization. These experts are an integrated components within the larger network, not individual domain-specific language models where prompts are routed to via the gating network, though they could theoretically be developed this way too.
The MoE concept dates back to 1991 (Introduced in this paper: Adaptive Mixture of Local Experts) but has gained renewed attention through its successful application in large-scale LLMs, particularly with the introduction of Mixtral LLMs. In a transformer-based architecture, experts usually replace the feedforward network positioned after the attention and normalization layers.
Figure 2: Mixture of Experts in a Transformers architecture
The MoE architecture offers distinct advantages. Its primary benefit lies in its cost-effective inference while enabling comprehensive sparce learning during training. DeepSeek’s architecture contains 671B total parameters, but only 37B are activated during inference. However, this efficiency comes with a trade-off: the entire model (all 671B parameters) should be loaded in GPU VRAM during inference. Furthermore, training this architecture is associated with challenges. For instance, consider the following question: how to effeciently load-balance the experts load during training to prevent signle or few experts overfitting?
DeepSeek R1
DeepSeek-R1 marks a landmark in AI development timeline. It is the first model that shows LLMs can self-learn reasoning via reinforcement learning in a large-scale setting. This has been prominently proven with DeepSeek-R1-Zero model where it showed that pure reinforcement learning could yield impressive result eliminating the need for SFT. This comes with the cost that its capabilities outside reasoning domains are hindered.
This section starts by first introducing R1-Zero. Building on that, it discusses the development pipeline of R1. Finally, it concludes by presenting the interesting conclusions they presented for R1 distillation to smaller models.
DeepSeek-R1-Zero
DeepSeek R1-Zero is a fascinating model given its training recipe. The motivation for training this model was to address the following question: Can we develop reasoning capabilities from pure RL only, without any SFT?
To approach this question, they started with DeepSeek-V3-Base. They prompted it with a simple template where the model had to put its thinking process between
RL in this stage, via its GRPO, does the following:
- reward the model if it correctly reaches to the final answer (in cases where the task is closed-form with designated output).
- rewared the model if it maintains a user-friendly format.
- asks the model to produce text with distribution close to the correct response.
The model generates many responses with very high temperature (to gain variety). This GRPO method, then, ranks these responses according to the above constraints. Why the language formatting is important here? Interestingly, they observed that R1-Zero tends to mix languages and produce text that is hard to understand while trying to reach to the final answer. While this can be an emergent capability to learn from various lingual representation and settings during the CoT (thinking) process unlocked via RL, this kind of output is not user-friendly and hard to crack for public use. This constraint ensures the model to follow a user-friendly format throughout its response. This may slightly affect the model performance, but it make the model outputs more readable and user-friendly. The last constraint is useful in cases of creative writing and open-ended discussions.
After convergence, the model performance on AIME 2024 jumped from a modest 15.6% to an impressive 71.0%. When they let the model generate multiple solutions and take a majority vote (what they call consensus@64), it reached 86.7%. On Math-500, they reached 95.9% and achieved 1444 rating on Codeforces benchmark.
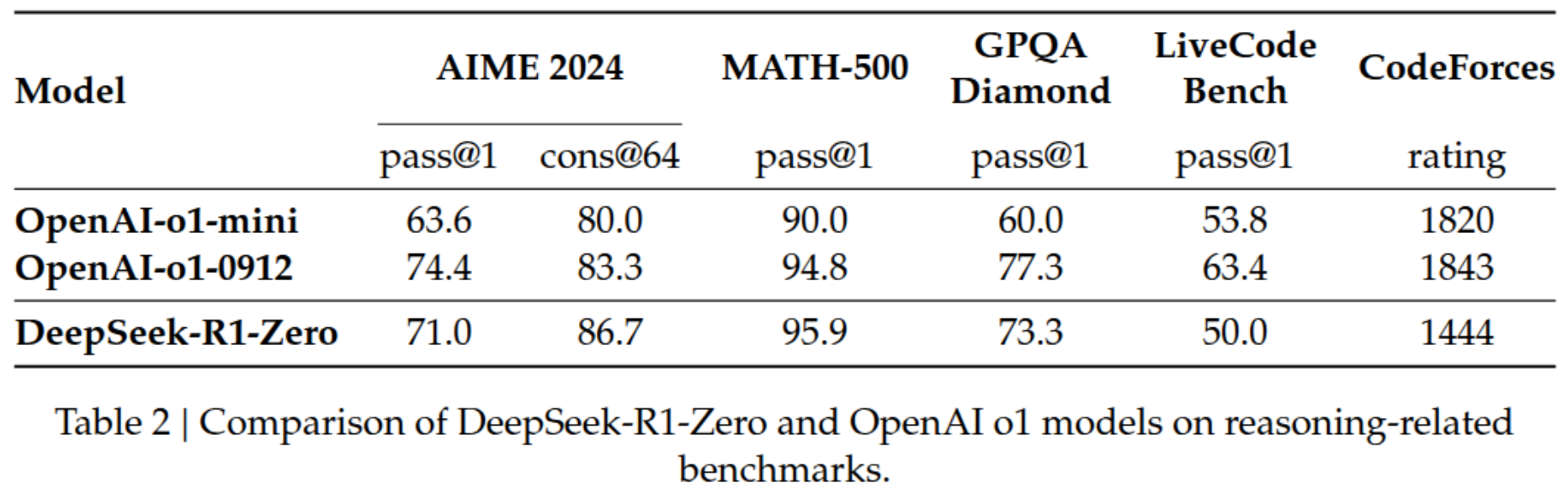 Figure 3: R1 performance on some benchmarks
Figure 3: R1 performance on some benchmarks
One of the most interesting moments during its training was what the researchers called the “Aha moment.” During training, the model started developing human-like behaviors similar to how humans think. It would sometimes stop mid-solution and say things like “Wait, wait. Wait. That’s an aha moment I can flag here” before correcting its approach. It learned to verify its work, try different solution methods, and even allocate more thinking time to harder problems.
 Figure 4: A DeepSeek-R1 Ahaa moment!
Figure 4: A DeepSeek-R1 Ahaa moment!
What’s particularly interesting is how the model naturally learned to use longer chains of thought as training progressed. Looking at the below figure, you can see a clear upward trend in the average response length during the RL process. The model started with relatively short responses (around 500-1000 tokens) in the early stages but gradually increased its reasoning length to nearly 10,000 tokens by the end of training. It seems that the model thinks that longer, more detailed reasoning chains led to better results. The graph shows some fluctuation (represented by the light blue shading), suggesting the model was actively experimenting with different reasoning lengths rather than following a preset pattern.
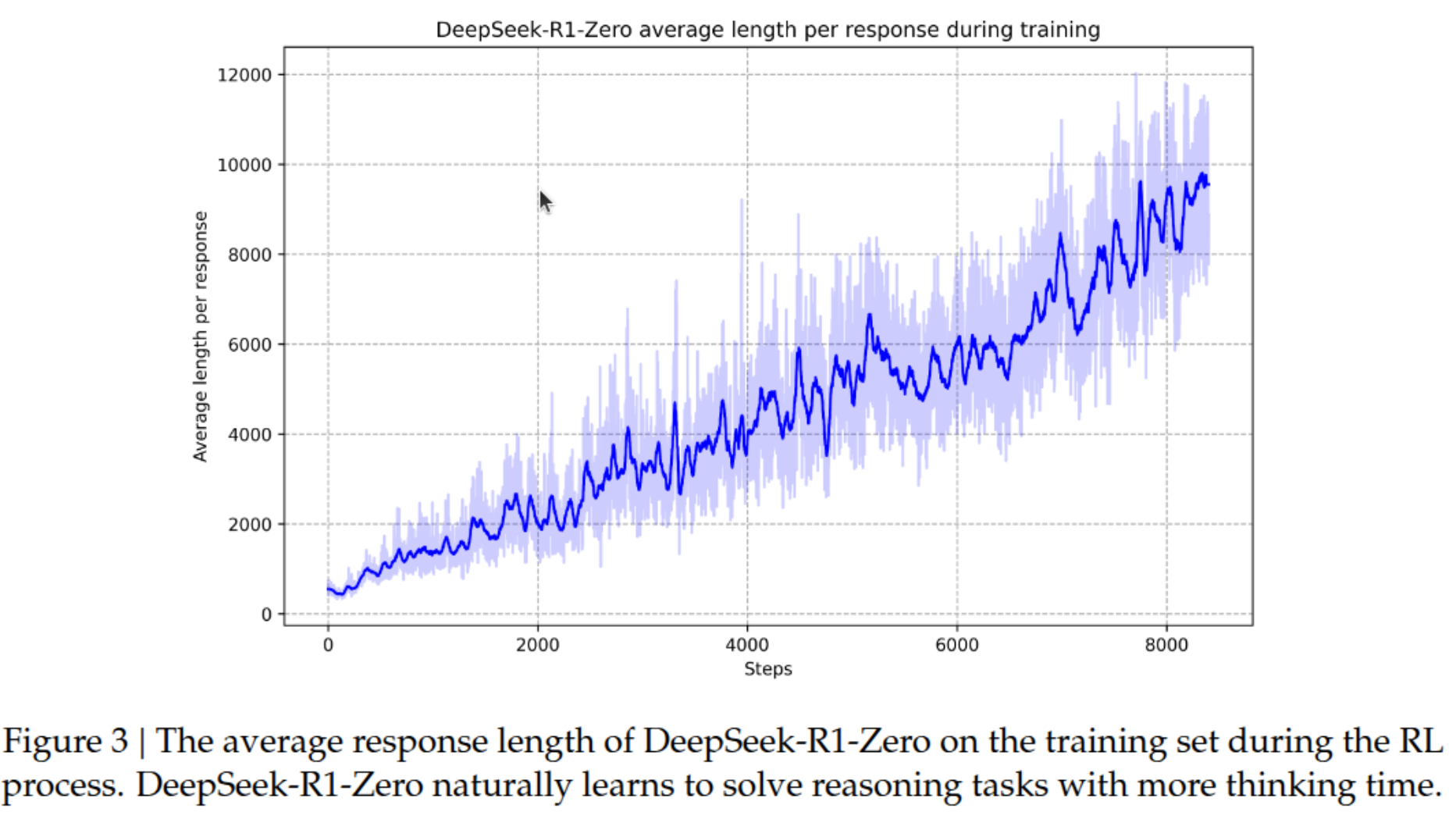 Figure 5: CoT response length over training steps
Figure 5: CoT response length over training steps
R1-Zero, with its surprising performance on reasoning tasks, still suffers from issues of bad formatting and language mixing. Its performance on other downstream NLP tasks is also hindered due to the lack of SFT. Consequently, DeepSeek performed further refinements to produce a user-friendly model that is suitable for public use. However, R1-Zero served its purpose proving that pure reinforcement learning can teach the model to reason, and learn by its own.
R1 development pipeline
DeepSeek R1 is an improved version of R1-Zero trying to make it suitable for public and general use with polished, user-friendly outputs. To achieve this purpose, they performed some refinements combining the bests from both lands: SFT fine-tuning and RL. DeepSeek R1 development can be very briefly illustrated in the following sequence of steps:
- SFT Cold Start fine-tuning of DeepSeek V3-Base -> DeepSeek-V3-Cold-Start
- RL training on DeepSeek-V3-Cold-Start -> DeepSeek-V3-RL.
- New SFT generated from DeepSeek-V3-RL combined with another SFT data generated from DeepSeek-V3-Instruct. Let us call this data post-RL-SFT data.
- DeepSeek-V3-RL fine-tuning on post-RL-SFT data -> DeepSeek-V3-RL-SFT
- Finally DeepSeek-V3-RL-SFT undergoes another round of RL training where this step produces DeepSeek-R1.
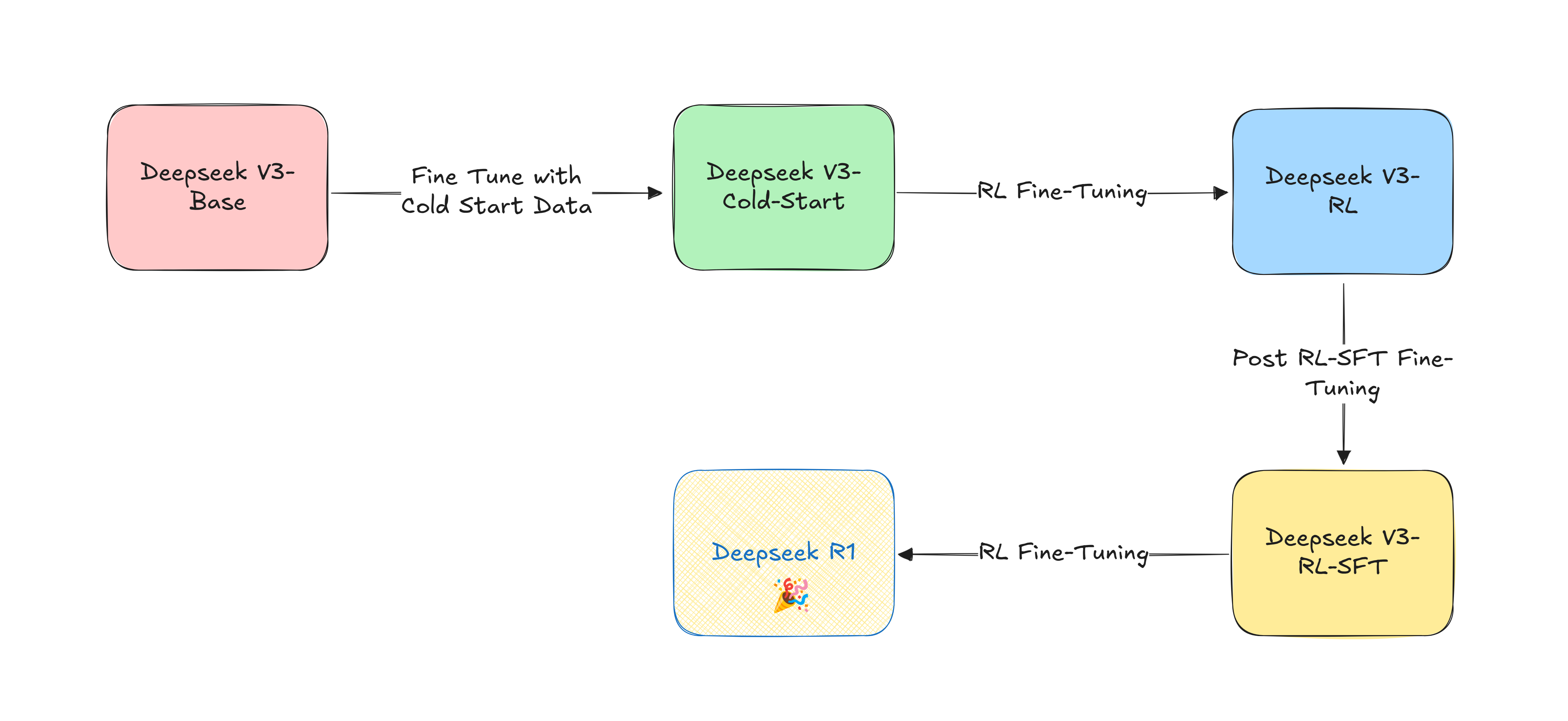 Figure 6: DeepSeek-R1 development pipeline
Figure 6: DeepSeek-R1 development pipeline
Discussing this pipeline in further details, they first start by fine-tuning DeepSeek-V3-base with data they called cold start data. This data consists of thousands of high-quality SFT datasets. The reasoning SFT data was collected via few-shot prompting with long CoT on DeepSeek-R1-Zero. The generated samples undergo verification steps with rejection sampling. They also extend this verification to human annotatation to maintain a high-quality constraints. This seems to play a major role in giving the model an overview of SFT settings, beside, of course, its important role in maintaining stable fine-tuning for the upcoming phases, alternating between SFT and RL reasoning setups.
After this initial training, they performed reinforcement learning on the DeepSeek-V3-Cold-Start checkpoint. This resulted in DeepSeek-V3-RL. Once this first round of RL training converged (meaning the model got really good at reasoning), they used this improved model to generate new training data. In oder to ensure further user-friendly output, they added another language consistency reward to the GRPO group of rewards mentioned above. For the generated responses, they only kept the best, filtering out anything with mixed languages, overly long paragraphs, or messy code blocks. They combined this with some regular language tasks (like writing and answering questions) to create a more well-rounded training set. They, then, fine-tune DeepSeek-V3-RL with this generated data to obtain DeepSeek-V3-Rl-SFT
Finally, another round of RL is applied on the DeepSeek-V3-Rl-SFT checkpoing. This last fine-tuning step yields DeepSeek-R1. This iterative approach paid off. The final model, DeepSeek-R1, almost maintains all the impressive reasoning capabilities of R1-Zero but presents its solutions in a much more user-friendly way.
R1 distillation to small models
After developing R1, they explored further practical angles to leverage such advances to small, more economical models. Basically, they tried to approach the following two questions:
- What is the effect of reasoning data fine-tuning on the economical LLMs?
- Are economical LLMs better trained from scratch with reinforcement learning or distill knowledge from powerful large RL reasoners?
What we mean by distillation is the smaller model will be fine-tuned on the large LLM reasoner outputs. For fine-tuning, they collected 800k samples from R1 and use them to fine-tune various smaller models, ranging from tiny 1.5B parameter versions to larger 70B ones using both Qwen and Llama architectures.
The results were surprising. Their 7B model (DeepSeek-R1-Distill-Qwen-7B) outperformed GPT-4o-0513 across many benchmarks, while their 14B version surpassed QwQ-32B-Preview despite being less than half its size. Most impressively, their 32B model achieved 72.6% on AIME 2024, 94.3% on MATH-500, and 57.2% on LiveCodeBench.
Another key finding they report from these experiments: distilling knowledge from R1 worked better than trying to train smaller models directly with reinforcement learning. When they applied R1-Zero’s RL approach to a 32B model, it only matched QwQ-32B-Preview’s performance. But the distilled version significantly outperformed both, suggesting that transferring knowledge from larger models is more effective than training smaller ones from scratch.
Final thoughts
To give a concise summary, DeepSeek introduces the following Ahaa moments in the LLMs research community:
- RL can completely replace supervised fine-tuning phase of LLMs development pipeline. However, cold-start data can be added for training and fine-tuning stability.
- Although current approaches for (RHLF) uses a reward model to score model responses then fine tune the LLM with this reward model using optimization methods like PPO, they showed that GRPO alone can perform both by scoring multiple LLM responses and score them relative to each other.
- They showed that LLMs can be good SFT data generators.
- They showed that distilling strong reasoning LLM to smaller models is more promising than training the small model with reinforcement learning.
DeepSeek V3
The introduction of DeepSeek-R1 would not be possible without the introduction of DeepSeek-V3. This model is the underlaying engine that drives the whole innovation of R1 and R1-zero. As introduced earlier, DeepSeek-V3 is a Mixture-of-Experts (MoE) language model, featuring 671B total parameters while activating only 37B parameters for each token during inference time. The developers incorporate multiple architectural innovations to achieve both efficiency, impressive, and strong performance at this large scale.
The architecture consists of 61 transformer layers with a hidden dimension of 7168. For attention, it uses 128 heads with a per-head dimension of 128. While using standard FFNs in the first three layers, all subsequent layers utilize MoE with 1 shared expert and 256 routed experts. For each token, 8 experts are activated along with the shared expert. This architecture allows DeepSeek-V3 to achieve impressive performance while maintaining efficient training and inference. The model was trained on 14.8 trillion diverse tokens with remarkable stability.
This section indents to provide a brief introduction to the model, they key innovations made while training it, which made it different than other typical LLMs. Below is a list of innovations and tricks they employ to achieve such performance.
Multi-head Latent Attention (MLA)
DeepSeek-V3 utilizes Multi-head Latent Attention (MLA), a technique carried over from DeepSeek-V2 for efficient inference.
For a glance, the attention mechanism is a mathematical operation that calculates scores (called attention) between sequence tokens. Each word is represented by 3 vectors called keys, values, and queries. The bottleneck here is that the number of keys, queries, and values grows linearly with the sequence length. That is, for longer sequences, the attention mechanism needs to perform more matrix operations adding more cost, especially during inference. In recent studies, caching the keys and values during inference has been shown to be a notable performance boost. However, DeepSeek advanced this one step further.
What MLA presenting (very briefly) is that they transform the keys and values into a lower dimension by down-projecting it with a lower-ranking matrix. This transformation is cached during inference. During training where they want to attain the dimensionality of these two matrixes, they upper-project them with a higher-ranking matrix. This trick allows for faster inference while maintaining intact performance during training.
Auxiliary Loss Free Load Balancing
DeepSeek implemented a MoE architecture. Following the hypothesis that parts of human brains are always active for all kinds of responses, they made a set of experts always active during inference. However, this introduces challenges on which expert got selected by the gating mechanism and thus has dominance during training and inference. This leads to inefficient training and waster compute during inference. For that sake, a loss-based load-balancing mechanism was introduced. Although it is effective, it confuses the training objective with its added gradients as the model will learn two objectives now. How to best select the best token and how to best balance its experts impairing the model performance as an additional regularization term. The innovation introduced by DeepSeek here is that they introduced a loss-free load balancing mechanism for the experts. This method does not rely on an auxiliary loss (as introduced in previous research works).
Multi-token Prediction
Another key innovation in DeepSeek-V3 is its multi-token prediction capability. This trick was inspired by a previous research. However, they showed that this trick can also be scaled to this large number of parameter settings. The idea is simply rather than just predicting the next token, the model can predict multiple future tokens simultaneously through a causal chain of predictions. The future tokens after the next token are predicted with a shallower network compared to the main LLM. This is only activated during training. However, it is disabled during inference.
Infrastructure and Training
Training large models like DeepSeek-V3 requires special attention to the training infrastructure. The model was trained on a cluster of 2048 NVIDIA H800 GPUs. The training framework, called HAI-LLM, is a lightweight framework built by DeepSeek engineers from scratch. The framework implements what they call DualPipe algorithm, allowing efficient pipeline parallelism by overlapping computation and communication. To shade some lights why this algorithm is useful, let us have a bit of a background on LLMs training stages.
As any neural network, the LLM needs first to perform the forward pass, calculate the loss, and gradients, then, perform the backward pass where it updates the weights and biases using an optimizer like Adam. This pipeline is smooth when the model is small and can fit on a single GPU. However, when training a large model that could span over multiple GPUs on multiple nodes (maybe you need to take a look on model parallelism?) this pipeline becomes ineffecient as some nodes become idle, waiting for forward and backward calculations. Previous training schedules already introduced where they were able to redunce the number of bubbles in the cluster (bubbles are the idle nodes), see: https://arxiv.org/pdf/1806.03377 and: https://arxiv.org/pdf/2401.10241. DualPipe builds on this work where they introduce two more points:
- They first split the forward and backward into further fine-graned stages to improve their computaiton parallelsim.
- They followed a bidirectional approach. They duplicates the parameters the device holds and run to parallel micro-batch on each copy. While this will introduce another computation and communication overhead, it further improves pipeline parallelism. I strongly recommend reading this elegant post: https://dataturbo.medium.com/deepseek-technical-analysis-4-dualpipe-672d0ef63ee6 before reading DeepSeek paper on this topic.
FP8 Training
One of the major advancements in DeepSeek-V3 is its pioneering use of 8-bit floating point (FP8) precision for training. Why this is important? Usually, training large language models requires high numerical precision (like FP32 or FP16) to maintain training stability. However, this comes with high memory and computational costs. DeepSeek showed that it is possible to train such large models with FP8 precision without compromising the training stability. They follow and improve on previous research (FP8-LM) introducing this idea at scale. It is also a good opportunaty to recall the BitNet paper here as well.
The framework they followed is a mixed-precision framework where GEMM operations (General Matrix Multiplication) are performed in FP8 and their outputs are upscaled back to FP32. However, other sensitive operations like attention, layer normalization, and embeddings are kept with FP32.
The team improved over this mixed-precision framework by introducing a fine-grained mixed-precision framework to overcome challenges due to this lower precision. Examples of these challenges are unstable training due to overflows and underflows. They group model parameters in small tiles (1x128 for activations and 128x128 for weights) and quantize each group independently. This helps manage outliers that typically cause training instability in low-precision training.
Among of the other tricks to introduce is the use of a smart accumulation strategy where intermediate computations are promoted to higher precision at regular intervals. This ensures that despite using FP8 for most operations, the critical accumulation of gradients remains accurate.
Conclusion
DeepSeek’s R1 model represents a significant breakthrough in AI progress, demonstrating that pure reinforcement learning can effectively teach language models to reason without supervised fine-tuning. This was achieved through their innovative R1-Zero model, which later evolved into the more user-friendly R1 version. The success of their approach was further validated when they found that distilling knowledge from R1 to smaller models was more effective than training smaller models directly with reinforcement learning. Built on their V3 architecture, which employs novel techniques like Multi-head Latent Attention and FP8 training, DeepSeek managed to create a cost-effective solution that rivals or surpasses leading Western models. I really hope this model presents a milestone towards furher democratization of LLMs to wider audience further unlocking its couplilnng with close-source enterprises.
Before ending this post, I would like to give a special Thanks for Ahmed Ashraf for providing me with better post drawings. I really appreciate the effort.
Useful Links and resources:
Te following resources, beside the DeepSeek papers, helped me a lot while writing this article. Hope you will enjoy reading/listening to them.
- 37- DeepSeek R1 Story & Innovation and the Global Tech Shake-Up
- DeepSeek Technical Analysis — (1) Mixture-of-Experts: Read the full series. It is really a useful series.
- The Illustrated Deep-Seek-R1
- What is Mixture of Experts? (by IBM Technology channel)
- Mixture of Experts Explained (by huggingface team)
- Model Parallelism (again, by huggingface team)
- A Visual Guide to Mixture of Experts (MoE) in LLMs
- The History of Mixture of Experts
- DeepSeek-R1: RL for LLMs Rethought
- Debunking DeepSeek Delusions